Doing good in the age of AI
This is an edited version of my talk at Beacon 2023, a conference about tech for good, organized by better.sg
 When I was invited to be on the AI panel at Beacon 2023 by better.sg, I was having a hard time thinking about what I should share. I don’t think I have had enough experience in the area to really “advise” others about the future of AI or how the technology would progress. So I decided to share my experiences so far in using AI for good and the lessons I have gathered.
When I was invited to be on the AI panel at Beacon 2023 by better.sg, I was having a hard time thinking about what I should share. I don’t think I have had enough experience in the area to really “advise” others about the future of AI or how the technology would progress. So I decided to share my experiences so far in using AI for good and the lessons I have gathered.
My first lesson about doing good in the age of AI:
Don’t start with AI
That doesn’t mean we should ignore AI. It is the current technological trend. And trend brings attention. Trend brings money. Trend brings even more advancements that lead to a snowball effect of even more advancements. I’m aware of the need to ride the trend too. For many years, I have actively avoided saying that I work on AI research and intentionally said I work on machine learning research. But more recently I have switched my “pitch” because saying that I work on AI catches people’s imagination much better, and it opens up opportunities such as to speak at Beacon.
However, I think that the core of doing good is about solving problems, and that’s where we should start.

One of my earliest research problems is on transcribing speech, which is about converting human conversations to text. Of course, this is a gigantic and really difficult problem, so I tried to solve a much smaller problem, which is to transcribe foreign names in speech. For example, non-native English speakers like me pronounce certain words differently than the standard way. And especially if those words are names of people or places that are not in the dictionary, there is no place to look them up and help with the transcription. So I worked on this problem for a while, came up with a model, and got a few research papers published.
Sometime after that, the Amazon Alexa team in Boston contacted me. Alexa is Amazon’s smart speaker that is very good at taking voice commands and acting upon them. And their team asked me about my transcription model. Amazing, right?
Can you guess what algorithm I used for the model?
The glorious “if-else” technique. It was essentially a direct translation of my intuition on how I would transcribe Vietnamese spoken words into text. For example, if the word sounds like it ends with a strong breath between our teeth, the model would mark it with an “s” ending, else I would look into the next word. Hence the “if-else” approach. I baked hundreds of these conditionals into the model.
So why “if-else” and not something more fanciful? One thing is that it was 2014 when I came up with the model. I didn’t know about deep learning back then. But then the call from Alexa team was in 2020, and I found out that what was being used in Alexa at the time was not that much different from thousands and thousands of “if-else”. What’s the lesson here? I will come back in a bit.
Another problem that intrigued me is that I want to see how my brain “fires” when doing a certain task. At the time, I was working on my PhD in machine learning for neuroscience. I wanted to understand our brain better and hopefully, that can help me understand machine learning models better. Because of that intention, I wanted to look at different patterns of how our brain is activated when doing different tasks and see if that can give some insights into how the brain works.
The most common way to do this is to do a Google search for the task, such as “throwing a ball” and read the research papers studying that task. They might report a table like below that tells the 3D coordinates of where the activations are reported. Can you tell where these places are in the brain? I can’t.
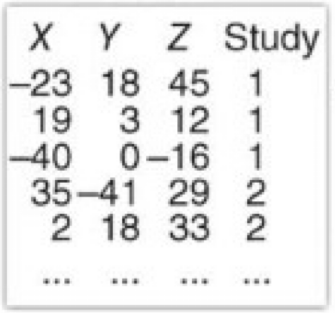
Can you tell which parts of the brain are activated for “throwing a ball” from these numbers?
So I thought there should be a simpler way to do this lookup. I created a model called braininterpreter.com that is meant to be a Google for brain activations. You can enter a search query like “Listening to music” and then see how our brain is activated as reported by research studies.
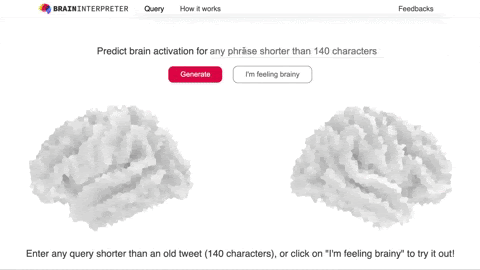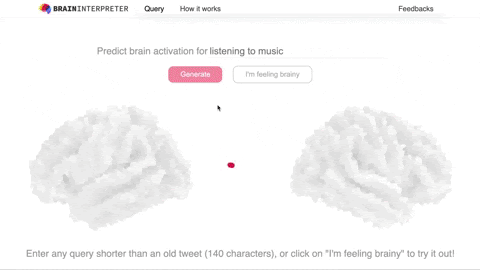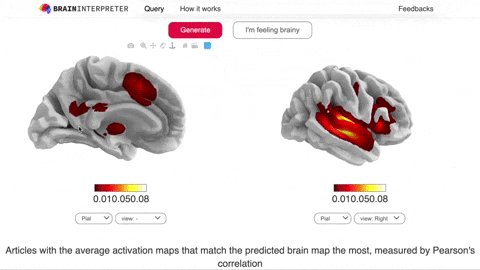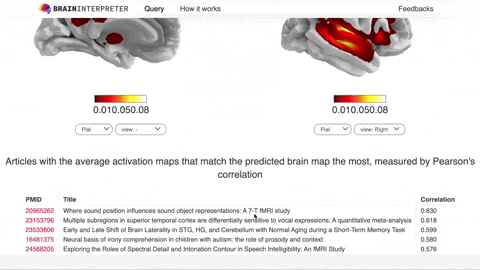
Now, can you guess what algorithm I used for the model?
This time, I did use a neural network. The reason is that neural network is very good at learning the complex relationship between human texts and images.
The main lesson I learned from the two research problems is that problem determines the tools. If I were to do these research projects today, would I use the same approaches? Maybe, maybe not. It depends on what the problem looks like. If I understand the problem well, the approaches almost come naturally.
But is the statement above still true for real-life problems?
I think so because 99.99% of real-life problems are never technical problems.
Back to the present day, at Give.Asia, our vision is to inspire everyone to be a giver. And we found many many problems that we want to help solve.
One of the problems we found is that fundraising is difficult. You need to craft a good story, share it effectively, update your supporters, etc. And to compound these difficulties, most charities we work with who need to do fundraising are severely short-handed. It’s much harder for non-profit organizations, compared to for-profit companies, to attract all the talents needed for fundraising.
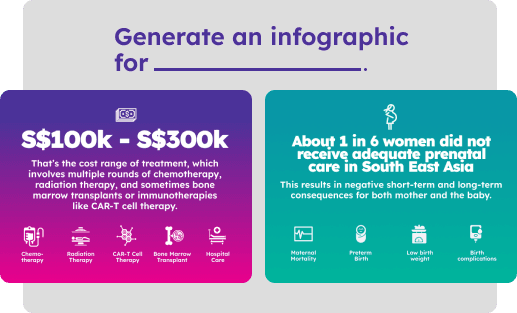
So we tried to help charities with fundraising by creating Sidekick AI, which is meant to be the assistant for fundraising needs. Sidekick AI can effortlessly generate campaign stories in any style, be it journalistic or activistic, whether the tone is meant to be emotional or optimistic. Sidekick AI can create infographics and images for your fundraising activities. For example, these infographics are automatically generated from a few simple text-based statistics.
Sidekick AI can also create promotional videos with one click. Practically every campaign on Give.Asia can have a video created in 5 minutes to summarise what the story is about.
Sidekick AI is already freely available for all our partner charities. And we hope to soon open-source the tool for other developers to build upon.
Another problem that we often hear from our givers is that it’s difficult for them to discover a match to their interest in giving. For example, how would I know which charities are doing well, which ones are efficient with their spending, and which ones work on the cause of my interest?
So about 2 weeks ago we started working on givepedia.org, which we envision to be a Crunchbase for charities. Crunchbase is this massive data directory of tech companies, and we want to do a similar directory of charities in Singapore.
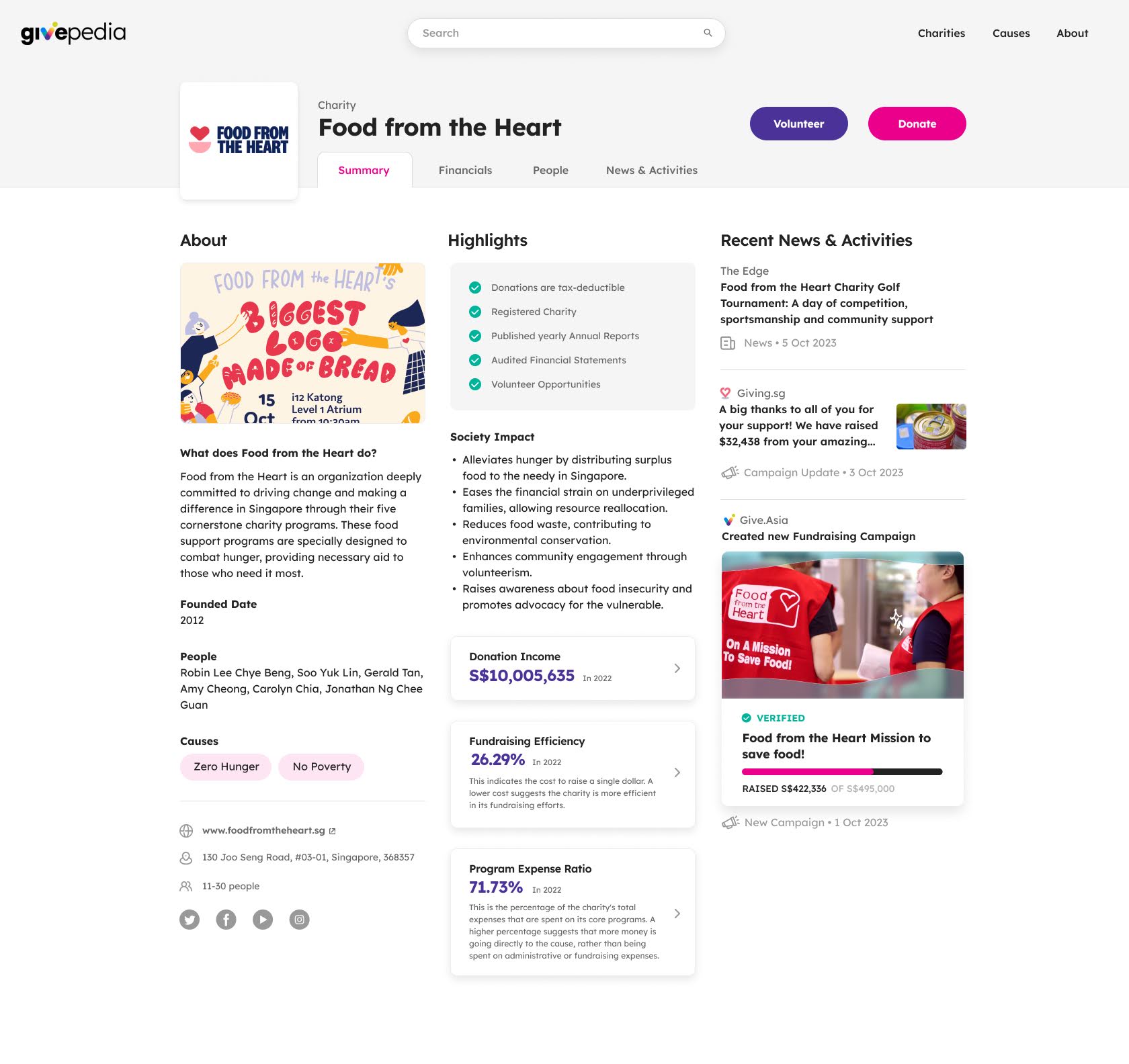
Givepedia is our Crunchbase for Singapore charities
On givepedia.org, you can very quickly get a look at different aspects of a charity, such as what they do, who are the people running the charity, and financial information that they have reported. We used a language model to synthesize multiple data sources related to charities and structure the data into bite-sized information that is easy to consume.
We also hope to soon make the data of givepedia.org accessible so other developers can build more applications on top of such information.
So if I am to summarize my lessons about doing good in the age of AI, those would be first, always start with the problem. Second, be obsessed. Be obsessed with understanding the problem to make sure it’s real to real people. Be obsessed with getting your tasks done. And finally, build things.
