Deploy a Neural Network to the Web
How to deploy a modern neural network as an (almost) production-ready web service
Here is what the final result looks like
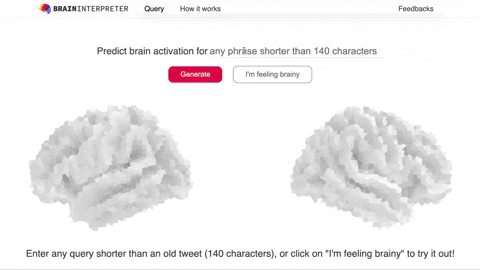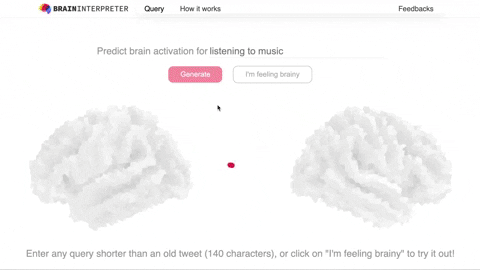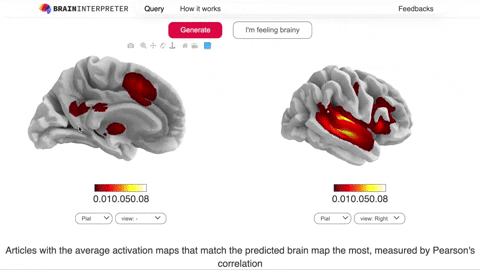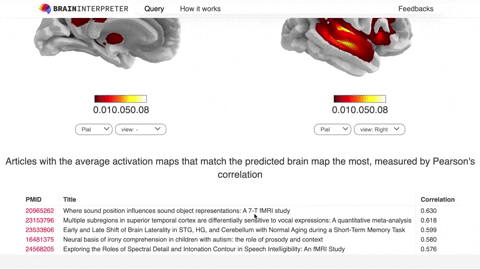
Overview
This guide demonstrates how to deploy a neural network, Text2Brain, as a web service for synthesizing brain images from free-form text queries. The final service is a “Google for brain images”, available at https://braininterpreter.com/
This guide is a continuation from the MNIST Digit Classifier as a Web Service guide. The basic setup and workflow in this guide can be applied to many other web-based services that rely on a machine learning model’s prediction, for example, segmenting an uploaded medical image.
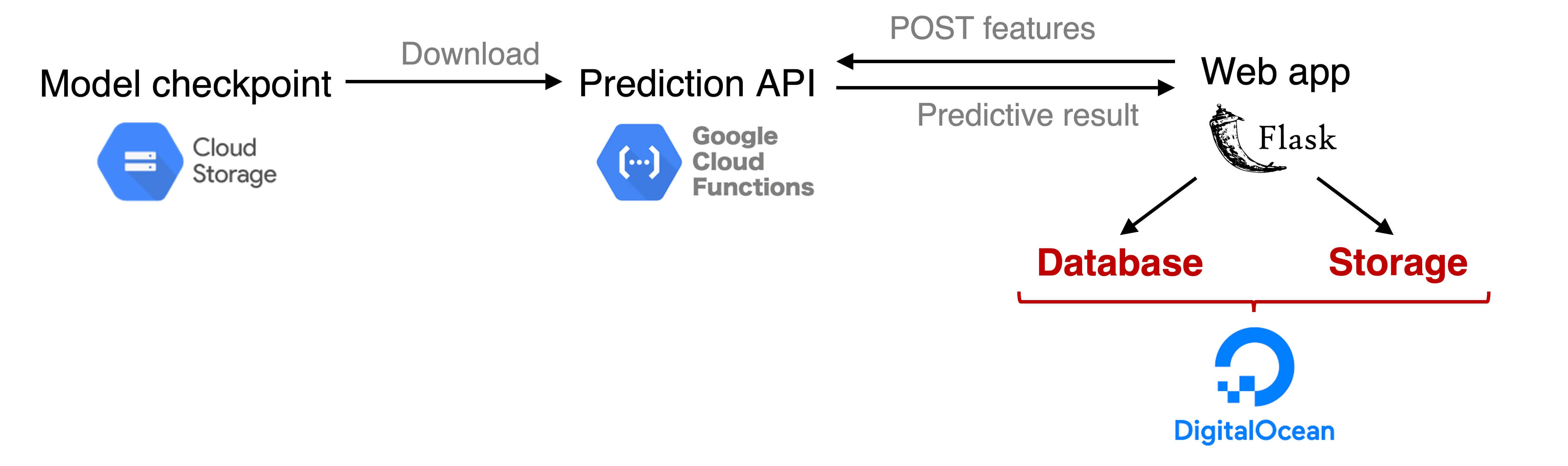 The figure above shows the components of the system.
While the previous guide shows the steps to connect a Flask web server running locally with a simple neural network hosted on a serverless computing node, this guide adds the extra components (in red) to host the web server online and make it (almost) production-ready.
The figure above shows the components of the system.
While the previous guide shows the steps to connect a Flask web server running locally with a simple neural network hosted on a serverless computing node, this guide adds the extra components (in red) to host the web server online and make it (almost) production-ready.
The components of the system are:
- Model checkpoint: the neural network’s weights uploaded to Google Cloud Storage. The weights will be downloaded and loaded into the model.
- Serverless HTTP prediction endpoint: functions on Google Cloud Functions that (a) receive input features sent from the web interface (b) make prediction, and (c) return the prediction to the web app.
- Web app: a Flask web app to handle user input (a text query) and present the predictive result. This webserver will be deployed to Digital Ocean.
- Database & Storage: SQLite database and storage to save predictive results.
All source code relevant to this guide can be found at https://github.com/ngohgia/text2brain_server.
Set up Google Cloud Storage & Functions
Make sure to check the MNIST Digit Classifier as a Web Service guide for a deploying a basic neural network to Google Cloud and connect it to a local web app.
Text2Brain model was proposed in our paper Text2Brain: Synthesis of Brain Activation Maps from Free-form Text Query with the source code available at https://github.com/ngohgia/text2brain.
Upload model checkpoint and assets to Google Cloud Storage
- Create a Google Cloud Project (GCP). Note that the project’s name, e.g.
text2brain-demo, and the project ID, e.g.text2brain-demo, will be used in later steps. The project ID can be renamed under the project Dashboard -> Project info -> Go to project settings. - Set up Google Cloud Storage as in the previous guide. The bucket’s name, e.g.
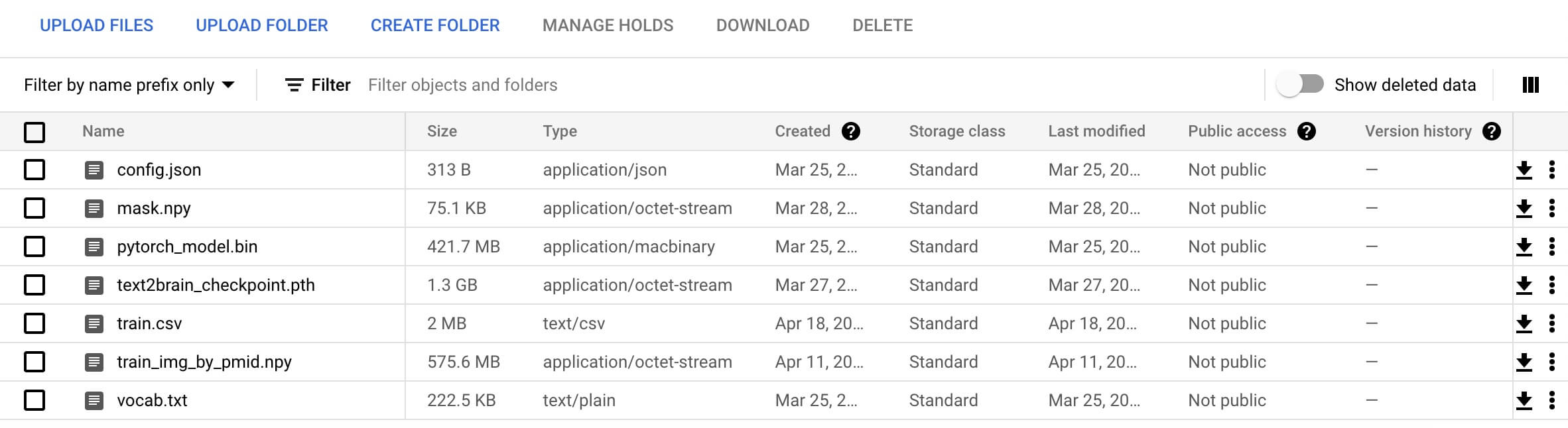
tex2brain, will also be used in later steps. - Download Text2Brain checkpoint and assets from Google Drive:
text2brain_checkpoint.tar.gz: model checkpointtrain.csv: consists ofpmid,title, andauthorof the articles in our training datatrain_img_by_pmid.npy:10574x28542numpy array, with10574equals the number of training articles (same number of rows as intrain.csv) and28542equals the number of brain voxels.train.csvandtrain_img_by_pmid.npyare used to find the training articles that best match a predicted brain image
- Download uncased SciBert pretrained model from AllenAI S3.
- Uncompress
text2brain_checkpoint.tar.gzandscibert_scivocab_uncased.tar - Upload all assets to the Google Cloud Storage bucket. The bucket should look like the following:
Set up prediction code on Google Cloud Functions
- Set up a Google Cloud Functions instance as in the previous guide.
- Choose your function name e.g.
tex2brain_demo - Make sure to have
Allow unauthenticated invocationsturned on to receive requests from the web app - For the region select ``us-east1’’ to avoid potential deploy error
- Under Create/Edit function -> Trigger -> HTTP, unchecking ``Require HTTPS’’ for debugging since the request will come from your localhost without HTTPS
- Under
Runtime'', set **8GB** forMemory Allocatedto fit the model and increaseTimeout’’ to 540 seconds to make sure the model doesn’t time out
- Choose your function name e.g.
- Upload all the code from the google-cloud-function-src directory to the newly created instance. The source code consists of the following files:
requirements.txt: list of required pip packagestext2brain_model.py: model definitiondecoder.py: 3D CNN as the image generatorlookup.py: utility functions to find training article with the average activation pattern that best matches the predicted brain mapmain.py: the main file that returns a predicted brain map for a text query contained in an incoming request. Make sure to update the constants specifying the necessary paths at the top ofmain.py
- Set Entry point as
predictreplacinghelloWorld - For a new prediction, the steps are similar to the MNIST classifier guide:
- If the model Text2Brain is not initialized, the checkpoints and assets are downloaded from the Google Cloud Storage bucket and the model is initialized. Note that this step can take several seconds, while the actual inference invocation only takes a fraction of a second
- After the model has been initialized, the model takes in
queryfrom the incoming JSON request and runs inference. The prediction is a 3D brain image, which is then masked with the brain to produceprednumpy array of length 28542 - Look through all the activation maps of the training articles and return
related_articlesthat contains the top 5 most articles with (masked) activation maps that best match the prediction, measured by Pearson’s correlation - Return the JSON response with
predandrelated_articles.
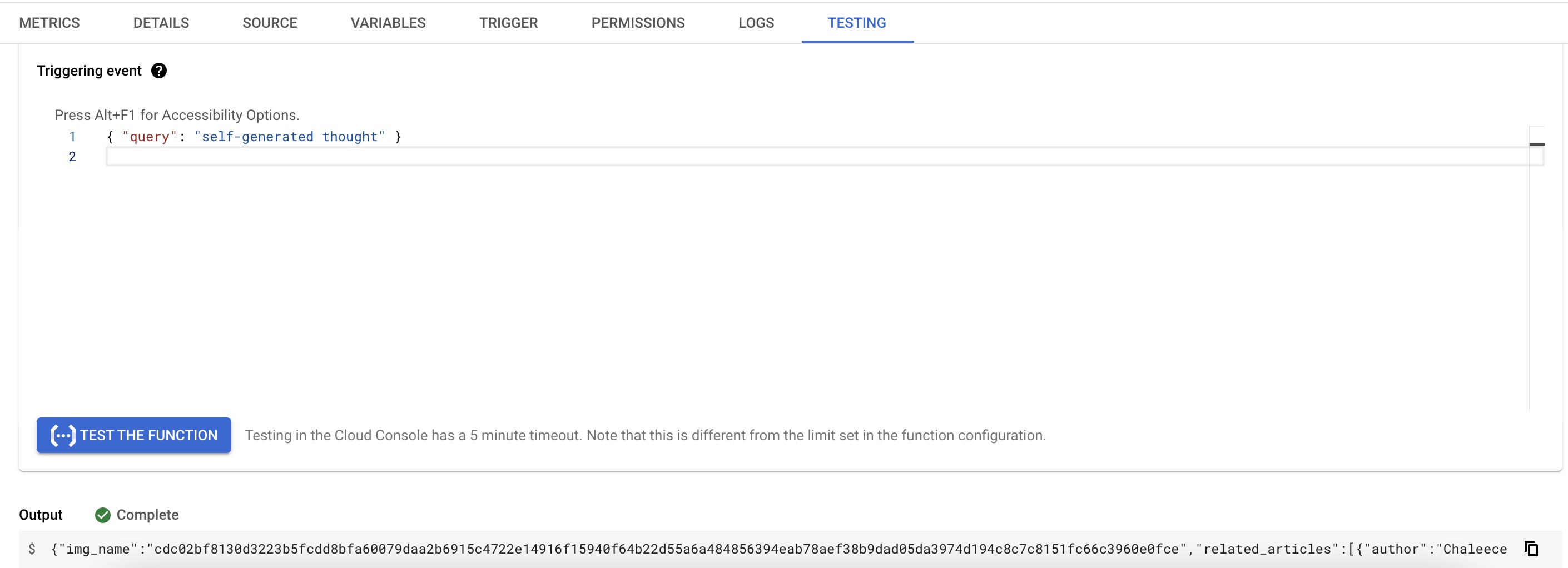
Make sure to check that the deployed function can execute and return the expected JSON response for an incoming JSON request, e.g. {"query": "self-generated thought"} similar to the screenshot below:
Flask + AngularJS Webpage
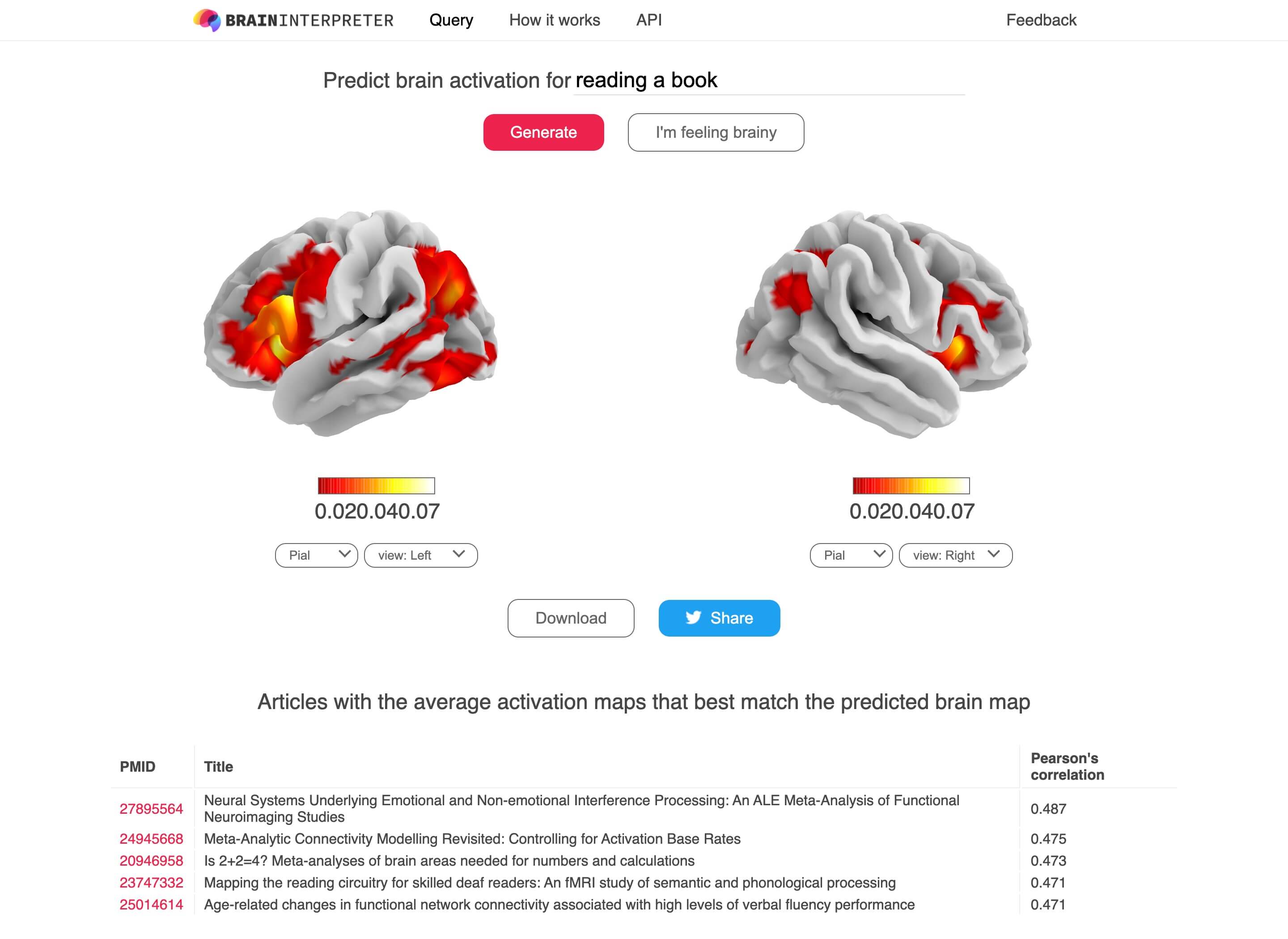
The core functionality of the webpage is simple: (1) takes in the text query input (2) sends the input query to the Google Cloud Functions HTTP endpoint and receives the returned response (3) renders the predicted activation brainmap (with the exceptional nilearn library) and displays related articles. Other components such as AngularJS are meant to add some “delight” to the users with dynamic user interaction.
On the other hand, some of the bells and whistles in the Text2Brain server’s code are meant to reduce response time (or the illusion of responsiveness). In Text2Brain case, the inference time contributes a minor fraction of response time (less than 1 second) if the model has been initialized on the cloud (which takes several seconds). Furthermore, retrieval of prediction, finding related articles, and rendering of results can take longer than the model inference. Here are some explanations on certain design choices that might be of interest to anyone else who wants to deploy a demo of their machine learning model:
Local vs cloud storage of prediction results
“Local” storage here means the same machine that the web server is located. The choice of using local vs cloud storage (such as Google Cloud Storage) depends on the use case of the model. Local storage is relatively faster and cheaper in retrieving results, which might be good for returning the same result repeatedly. For example, in Text2Brain case, it’s likely that the same common phrase would get queried often, local storage seems to be a better option. On the other hand, cloud storage service (or any other cloud service) removes the need for maintenance, such as regular backup of data. In cases that the stored data is critical (e.g. clinical prediction), it might be a good idea to rely on specialized cloud solutions.
Database
Compare to the toy demo with the MNIST classifier, the biggest difference is the addition of a database for storing prediction results. For simplicity, SQLite was used for the database. As an example, Text2Brain server has only one table results with the following columns:
id: unique index of each rowtext: input query stringimg_name: unique hash string defining the predicted image’s namerelated_articles: JSON array (as a string) containing the training articles that best match the predicted imagecount: number of times the query has been made to the server. This is only for our curiosity at the moment, but can also be used more smartly
Choice of Web Hosting
Text2Brain server could have been deployed to Heroku, which takes care of the “dev ops” needed to set up a web server, such as reverse proxy, WSGI etc.
However, Heroku has a 500MB slug size, which might limit some applications, such as those that require large assets uploaded. For instance, an iteration of Text2Brain server requires the train_img_by_pmid.npy file (see previous section) for looking up the related articles, which would exceed Heroku’s slug size limit.
Digital Ocean offers a lot more flexibility, such as the number of CPUs, memory etc. at the expense of setting up the server by yourself. It might take a few trials but Digital Ocean has excellent guides and tutorials for such matters. For Text2Brain web app, here’s the setup:
- Droplet with 2 GB Memory / 1 Intel vCPU / 25 GB Disk + 100 GB Block Storage. The block storage is for storing prediction results
- Follow the initial server setup guide for setting up the droplet
- Follow the guide for setting up a Flask Application with Gunicorn and Nginx. Note that to use the environment variables with gunicorn, such as those needed in Text2Brain config.py, more
Environmentvariables need to be added to/etc/systemd/system/your-service-name.service, such as:Environment="TEXT2BRAIN_DB_DIR=/home/deploy/text2brain_server/db" Environment="TEXT2BRAIN_GCF_URL=path-to-your-google-cloud-function"
The illusion of Speed
As mentioned above, model initialization can be an order of magnitude slower than the inference time. On the other hand, an initialized model is cached on Google Cloud Functions for a short period of time, so if the model can be initialized before the user makes a new request, the response time would be significantly shorter than if the model has to be initialized after the request has been received by the cloud function. Therefore, when user lands on https://braininterpreter.com, the web app will render an existing result and also sends a request with an empty query to the model HTTP endpoint and causes the model to be initialized. As users are more tolerant to a slow response at the first load of a webpage, compared to when they want to get a new prediction quickly, this trick tries to get the Text2Brain initialized and cached for the user before they enter a query.
What’s next
This guide walks through some key steps in deploying a modern neural network to the web with some measures to ensure responsiveness of the deployed service. For this kind of web app to be used in non-trivial scenarios, several standard components need to be added, such as authentication, firewall (such as using CloudFlare), and more sophisticated caching.